As an enterprise architect with 20+ years of experience, I have witnessed many seemingly simple deployment architectures that have come back to bite clients once they are scaled from POC to enterprise-wide deployments. Often, they are forced to live with the choices for many years so I’d like to share some best practices with you so that you do not have to suffer the same fate.
As an enterprise architect with 20+ years of experience, I have witnessed many seemingly simple deployment architectures that have come back to bite clients once they are scaled from POC to enterprise-wide deployments. Often, they are forced to live with the choices for many years so I’d like to share some best practices with you so that you do not have to suffer the same fate.
1. Don’t choose a centralized data repository architecture
Back in the day when applications were centralized 3-tier or 4-tier architectures, a single database could store and service the monitoring data needs. Today, applications are composed of multiple services, which are hosted throughout the enterprise, often in different data centers. This creates potentially thousands of data measures for each application to monitor to determine the health and performance of the system. With both near real-time sampling frequencies for root-cause-analysis-of-errors and long-term data retention for expected-utilization and capacity-planning, the complexity of the monitoring data quickly rivals that of the application itself. Multiply these applications to the Enterprise scale and creating a timely, cost-effective storage-analysis solution becomes a non-trivial task.
Although a single data warehouse relational database solution for monitoring data provides a central aggregation for analysis, it comes with significant cost and performance overheads. To support a database or data warehouse capable of storing 10-100s TB of data or more is going to require specialized hardware and software that is very expensive to both buy and build but also to maintain over time. NoSQL systems offer a lower cost solution but they don’t provide the required ad-hoc analysis capabilities at the level of a high-end RDBMS. In either case, latency will be increased if you must send metrics from across the enterprise to a single, centralized database which is trying to manage 100’s or 1000’s of updates each second.
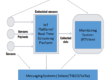
A better approach is to choose an intelligent, scalable and cost-effective federated data model with timely enterprise aggregations to analyze monitoring data. In this approach, you will have multiple, distributed data repositories, often in-memory, and deployed close to the source of data collection. This approach provides lots of advantages in building and maintaining an enterprise-wide monitoring platform including: 1) local data repositories can be deployed on cheaper commodity servers, 2) new repositories can be added as new departments and computing centers are added to the enterprise, and 3) latency is reduced since metrics are collected and stored locally and only the data needed at any given time is sent to the display server.
Remember that federating is cheaper and easier and still answers the same questions asked of a much larger and more complicated centralized repository.
2. Don’t get stuck managing 1000’s of agents
Name the oldest system in your company. How long has it been running 10 years? 20 years? You have just named the most successful application in the company. If you want your enterprise monitoring system to be just as successful, it will needs to be architected for upgrades and backward compatibility. Every year that the support group can pull off a successful upgrade, is another year added to the legacy of the architecture. The time you can’t upgrade software, is the time you decide to replace it.
Each instance of an architecture component adds to the complexity of the overall system making upgrades more difficult. In an agent-based model, 1000’s of instances of the agent will be deployed across every server in the enterprise. Each of the agents needs staff (and potentially down time) to install, test, and upgrade. Also, “big bang” upgrades (where all servers are upgraded in the same day or week) almost never happen, meaning that cross-version compatibility between the agent and the central server must be tested (and regression tested). If an application is on life-support (upgrades-updates are not possible but the application isn’t ready to be turned off) this cross version testing could go on for years. If you have to install software on systems owned by multiple customers, you have created a potential upgrade nightmare.
The best way to avoid a non-upgradable architecture is to avoid agents all together. An agent-less architecture makes it much easier to maintain your enterprise application monitoring platform over time because: 1)you won’t have to constantly be upgrading 1000’s of agents across the enterprise, 2) you’ll avoid the conflict of simultaneously upgrading systems owned by multiple customers who may not all be ready to upgrade at the same time and, 3) you’ll avoid any performance overhead incurred by deploying your own monitoring agents on each target machine, service or application.
It has been said that the total cost of ownership for an enterprise application breaks down to 7% installation and configuration and 93% maintaining that system over its 10-15 year lifespan. Smart choices in enterprise architecture can significantly reduce the long-term costs of maintaining your enterprise application monitoring platform so that you can focus your efforts on improving the performance and uptime capabilities of your mission-critical applications rather than your monitoring platform.
Have you ever been stuck in one of these monitoring architecture traps? We would love to hear your feedback. Send us your comments below to keep the conversation going.
——————
RTView Enterprise Monitor is an End-to-End Application Monitoring platform that uses an agent-less, distributed data storage/processing model. For more information on why RTView Enterprise Monitor is a great choice for your end-to-end monitoring needs, visit us at www.rtview.com.