It is easy to pull out the long list of features that a product must have to address the challenges inherent in monitoring a large estate of critical business applications across an enterprise. But I won’t do that to you here.
Everyone knows monitoring is important. If your apps run slowly or crash, you lose money, simply stated. Clearly you have to invest in monitoring … but how do you get the best return on that investment? The answer lies in understanding the nature and scope of the problem, and if it is addressed properly, the business value you can expect in return.
Naively, one might think that the greatest business value would come from a reduction in the mean time to repair problems, or in time spent troubleshooting. This is what most vendors will tell you. However, much greater returns on a customer’s investment can be derived from improvements in productivity, maximizing utilization of resources, and reductions in the amount of time wasted by expensive personnel doing unnecessary tasks.
I said I wouldn’t pull out the long list of features, so let’s focus instead on how SL Corporation’s RTView product can serve up signficant business value in three distinct areas, starting with an all-to-familiar problem: that Application Support people and Infrastructure people have a hard time talking to one another.
RTView Facilitates Collaboration Between Application and Infrastructure Teams
There has been a lot of excitement recently about DevOps, the practice of tightly integrating Application Development with IT Operations, in the hope that this might alleviate tension between these groups. Unfortunately, most organizations still manage applications and infrastructure separately and along lines of accountability. Individual groups are assigned responsibility for only one or a small set of technologies, posing serious challenges to collaboration and efficiency.
Infrastructure and middleware administrative tools often collect and display monitoring metrics, but Application Support people usually do not have permission to access the data collected there. System Management tools like OEM or HPOV collect and store all data centrally and limit collection intervals to 5 or 15 minutes in order to scale. The data contained there are similarly out of reach of Application Support people. So they end up building their own. The groups see different data and end up blaming one another.
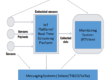
RTView takes a very different approach that facilitates collaboration. Stand-alone technology-specific modules, such as TIBCO EMS Monitor or Oracle WebLogic Monitor, can be installed locally by infrastructure teams to provide in-depth data collection, monitoring, alerting, and dashboards. By design, these modules are also “Data Servers”, accessible by RTView Enterprise Monitor components that Application teams can use to correlate information across multiple technologies in order to provide end-to-end visibility into the health state of their applications. This approach can dramatically reduce finger pointing when things go wrong, since the Application teams and Infrastructure teams see exactly the same data.
RTView Reduces Information Overload – Users See Only What They Need to See
Large organizations typically centralize monitoring and alerting in order to maintain standardization and control. Nice goal, but this generally suffers from a serious problem – too much irrelevant information. The alert management system in a large enterprise could have thousands of active alerts at any one time. The overwhelming task of wading through these to find what matters is left up to users, often with a home-grown filtering solution. Providing (useful) summary reports to management is next to impossible.
Within any organization, there can be many different application groups each with its own manager and support people. Each application is dependent on a specific set of underlying infrastructure and middleware components. RTView can be configured to maintain a “Service Model”, a hierarchical arrangement of all components into applications and groups to which they belong. This model can be manually created, auto-populated in many cases from application metadata, or imported from an external CMDB.
Using this Service Model, incoming information can be presented in a digestible fashion. Every user who logs into RTView is assigned a “role” which can be associated with a list of applications or groups for which that role is responsible. All alerts and monitoring metrics are filtered so the user sees only what is relevant to that assigned role. This dramatically reduces the amount of time wasted searching through irrelevant data, or responding to alerts that someone else should be handling.
Furthermore, the hierarchical model enables the automatic creation of summary views that can be provided to management. A business area manager may want to see just a few red/amber/green lights showing the health state of the applications in that department. When an indicator goes red, the right support person can be called. Chances are that person has seen the same indicator, and has already started investigating by drilling down to the detail data that was propagated up to the summary view. This is a vast improvement over the traditional model in which the “all-hands” war-room meetings are called to troubleshoot serious issues.
RTView’s Distributed Architecture can Scale to Very Large Organizations
A large organization might have one team managing a bank of TIBCO Business Works Engines, another dealing with a farm of Oracle WebLogic Servers, and yet another responsible for the VMWare virtual substrate on which everything runs. These services are typically supported on separate subnets for the Americas, Europe and Asia … serving up serious challenges for enterprise-wide monitoring. An intelligent distributed monitoring architecture is needed to meet these challenges.
RTView is highly modular and can be installed quickly and easily with a small footprint. This means that multiple stand-alone RTView collectors/monitors can be installed across different geographies and for independent infrastructure or middleware services. Each one maintains its own data collection, aggregation, analytics, alert processing, data archival and dashboarding. Yet, they can all work together seamlessly and efficiently to provide large-scale end-to-end monitoring for multiple independent Application Support teams.
This intelligent distributed architecture is completely unique to RTView and has been shown to scale to very large organizations, with hundreds of applications and tens of thousands of servers. In addition, the heterogeneous nature of the platforms on which applications are built today requires the kind of normalized, modular, technology package solutions that RTView provides as part of the complete RTView Enterprise Monitor product line.
RTView is used by hundreds of customers to monitor very large scale applications built on heterogeneous middleware platforms from Oracle, TIBCO, and IBM, as well as open source products. We’ve seen first-hand just how effective a solid, distributed, business-oriented monitoring architecture can be, and the business value that follows.
For a short introductory video about RTView EM, please go to the RTView Enterprise Monitor Demo