There are not many people who know that the number of atoms in the earth is almost exactly the square root of a googol (1.3 x 10^50) … which also means that if every atom inside the earth were itself an entire earth, the total atoms nested within would be about one googol. A somewhat geeky factoid, but an interesting way to visualize very large numbers and especially useful for impressing friends and family.
There are not many people who know that the number of atoms in the earth is almost exactly the square root of a googol (1.3 x 10^50) … which also means that if every atom inside the earth were itself an entire earth, the total atoms nested within would be about one googol. A somewhat geeky factoid, but an interesting way to visualize very large numbers and especially useful for impressing friends and family.
It can also put into perspective some of the frenzy around “Big Data.” We are at that point in the hype cycle where people are starting to realize that Big Data will not solve all the world’s problems. As with other exciting new technologies before it, we slowly wake to the realization that in fact a lot of work has to be done to put the new capabilities to practical use, and its applicability may be more limited than originally thought.
The use of large-scale parallel processing capabilities to search for patterns in an amorphous blob of unstructured data is particularly useful in applications like fraud detection, marketing optimization, finance, meteorology, and others with very large data sets. These were some of the original use cases that spawned Big Data solutions.
However, in the Application Monitoring space, a lot of vendors have jumped on the bandwagon and started promoting their products as Big Data solutions … something that I find a bit misleading. True, there are a lot of bytes in a big collection of log files, and searching for patterns to predict future outages is an admirable pursuit. But I see the problem very differently.
It has to do with what one might think of as the “shape”, or organization, of the data. In monitoring large-scale distributed applications across heterogeneous platforms, we are not collecting unstructured disorganized data. It is very much the opposite … data that are highly structured and clustered across multiple dimensions. The challenge that we face is not so much the volume of data (far less than a googol), but rather in dealing with its complex and multi-dimensional nature, or shape.
For example, a large banking operation will typically be collecting data in many different locations. Groups in Asia, Europe, and America might independently maintain their own instances of critical applications and locally acquire data relevant to monitoring them. At the same time, a central Enterprise Management group might require access to the data stored there, to generate reports or provide backup support.
Complicating this further, large organizations usually manage applications completely separate from the supporting middleware and infrastructure. Individual groups are dedicated to managing a large estate of a single middleware technology, such as the TIBCO Messaging platform, or the Oracle WebLogic Application Servers. Data relevant to monitoring those technologies are collected locally and used solely by those groups to maintain the health state of those services. Within these collections of technology-specific data, there is an even deeper complex hierarchy of Servers, Topics, Queues, Servlets, EJBs, and so on.
The problems created by the complex shape of all this monitoring data are many. Application support groups depend on proper functioning of the underlying middleware and infrastructure, yet they typically have no access to the data they need. Instead, they have to wait until a crash occurs, then they go ping the Middleware people to find out what went wrong. Management often has no idea what is the current health state of critical applications, or whether their huge investment in IT infrastructure is being adequately utilized.
A lot of money can get spent trying to catch the wave of Big Data pattern searching and predictive analytics, when in fact the source of most outages is usually not that complicated. Often, it is as simple as a server that has run out of memory or a queue that backed up. It’s just that users “didn’t see it coming” … a visibility problem. Most monitoring solutions are ill-equipped to deal with the complex structure and organization of monitoring data as described above, and as a result, the users who need the data the most are unable to get to it. This is not to say that anomaly detection is not a useful tool … it certainly is. However, I would argue that a very large percentage of problems encountered by users are caused by simple limitations in visibility of or access to data.
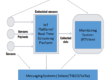
What is needed instead is a real-time Data Management System that addresses this problem. First, you need to be able to normalize access to data … not normalize the data itself, but rather the access to it. That is, to make any of the data collected anywhere in the organization available via a standardized API to anyone else in the organization, with the proper privileges of course. This is much more than just a simple REST API for data, as it must include historical as well as current data, and provide an easy way to convert all infrastructure and middleware monitoring data into a common query format.
A fully featured Data Management System for use with large-scale applications must also provide a way to summarize monitoring data in a way that reflects actual usage. It would be highly inefficient (and use costly network bandwidth) to transmit all data for a region to a central location for summarization. Instead, aggregations need to be performed locally yet be viewable both locally and centrally. Drilldown needs to be facilitated by an intelligent directory mechanism that identifies the location of all data and the means to access it without actually transferring the data. Activity on load-balanced application servers needs to be viewed in aggregate, rather than one server at a time, as it is in many existing monitoring systems.
These examples clearly show that the problem of dealing with Big Data in monitoring systems is more than a matter of searching for patterns in some central NoSQL database. It has a lot more to do with how to make data available to the people in the organization who really need it in a way that they can readily digest it. This is a very different problem from the one that most people think of as Big Data.
In order to keep this blog to a reasonable size, at this point I will refer you to other blogs I’ve written on this subject. For example: Enterprise Application Monitoring: The Business Value or What Failed: My App or My Infrastructure provide some details about how SL Corporation has addressed these challenges. More to come later …